
 当前位置:
当前位置:






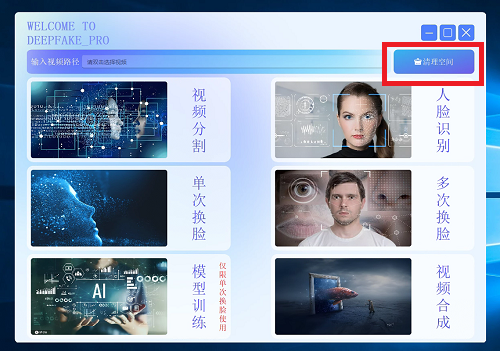
1. 双击图标打开软件,清理空间 避免前期输出干扰本次结果
2. 视频选择
双击输入框进行可视化选择 或 输入视频位置
![]()


注:单次换脸中,输入的视频应该是演员模仿视频
注:演员视频请..是25帧/s,如果录制视频不是25帧,请使用Pr调整
3. 视频分割
单击视频分割按钮,并耐心等待视频读入完成,过程约1-2分钟
![]()

在读入过程中请勿进行操作,待软件提示,视频读入完成后,可在文件夹D:\deepfacepro\core\workspace\data_dst中查看,如下所示
4. 人脸识别
单机人脸识别按钮,弹出人脸识别提示进度,等待进度条走到100%,关闭该进度窗口。

5. 模型训练(可不执行)
模型训练操作..单次换脸中执行,其目的是为了..演员和目标人物的表情动作一致性,当需要强化口型或表情动作时,可以执行该步操作。
单击模型训练按钮,弹出训练提示框
![]()
![]()
注:当使用新的视频素材时,推荐执行模型训练
注:模型训练中,注意观察dst损失,当降低到0.15以下会达到比较好的效果,大约需要耗时2~3小时
6. 单次换脸
单击单次换脸按钮,弹出单次换脸提示框,按住Tab键进入可视化换脸界面
![]()

在可视化换脸中,常用的操作为W/S 放大/缩小遮罩,E羽化遮罩
注:在单次换脸中,需要尽可能..目标人物面部的完整性,无需考虑替换是否自然,如下图。(注意英文输入法)

确认效果后按住Shift和>键全部导出
注意观察进度条,当进度到100%,关闭此窗口继续执行
7. 合成视频
单击视频合成按钮,耐心等待视频合成完成,大约需要2-3分钟
![]()



 全国咨询热线:18629408877
全国咨询热线:18629408877 